This post is part 3 of the "Automated Task Collection" series:
Keeping track of all of your tasks can be difficult when they are spread out over many different sources. If you want to keep track of items in one location, one option is to manually create todos in your chosen location and link them back, a drawback to this is it's all manual and you have to manage the tasks in two places now for each task and you have to remember to link them in. Another option is to automate this task creation and linking. You can also automate closing of the items when closed in one source or another. We are going to explore setting this up in n8n in a reusable way to make it easier to add additional sources in the future.
Tools Used
- n8n - Workflow automation tool
- Todoist - Task management application
- PostgreSQL - Our datastore
Note: Can be adapted to other tools
Reusable data to Todoist workflow
Decide on data model for input
Determine how we want to accept data from other sources. We will use this data model to create a workflow that will accept the data and then manage it in Todoist. I decided on the following model:
{
"key":"::SOURCE:IDENTIFIER::",
"title":"Task Title",
"url":"http://example.com",
"priority":1,
"due":null,
"labels":[],
"completed":true,
"section":"Current"
}
key will be used to identify a linked task in todoist and the database. This will be unique to each source and identifier. For example, if I have a task jira the key might be ::JIRA:ID::, or if you have multiple projects ::PROJECT-KEY:ID::. This gives us a unique identifier for each task that we can use to update the task if it already exists in Todoist.
section is a special case, I grabbed the section ids from Todoist by copying the link to the section eg: https://todoist.com/app/project/1111111#section-2222222 and then grabbing the section id from the URL. If you are using multiple projects and want to use sections, you will need to do this for each project.
Write workflow to accept the data model, check it against database and then manage in todoist
Create a workflow in n8n and add a Manual Trigger node, edit pinned data and create a few task items in the format above for testing.
Then create a Code node to set the section and default priority. Set mode to Run One for all Items. Example code here:
for (const item of $input.all()) {
item.json.priority = item.json.priority || 1;
item.json.dbkey = `%${item.json.key}%}`; // this is used to search the database for the task
switch (item.json.section) {
case "Current":
item.json.section = 111111111;
break;
case "Upcomming":
item.json.section = 222222222;
break;
case "Wishlist":
item.json.section = 333333333;
break;
default:
item.json.section = null;
}
}
return $input.all();
Then create a Postgres - Execute a SQL Query node to check if the task exists in the database. Set the query to the following:
SELECT
t.task_id,
t.content,
t.description,
t.added,
t.completed_at,
t.due,
t.labels,
t.checked,
t.url,
t.parent_id,
$2 AS key,
true as found
FROM todoist_tasks t WHERE content LIKE $1
UNION ALL
SELECT
NULL as task_id,
NULL as content,
NULL as description,
NULL as added,
NULL as completed_at,
NULL as due,
NULL as labels,
NULL as checked,
NULL as url,
NULL as parent_id,
$2 AS key,
false as found
where not exists (select 1 from todoist_tasks where content LIKE $1);
And set Query Parameters to dbkey,key.
Create Code node to merge the data with the database output. Set mode to Run One for all Items. Example code here:
const output = [];
for (const it of $input.all()) {
const data = $('Set Data').all()[it.pairedItem.item];
delete data.json.key
console.log("data", data);
var db = null;
if (it.json.found) {
db = it.json
}
output.push({json: {key: it.json.key, data: data.json, item: db, has_item: db !== null}, pairedItem: {item: it.pairedItem.item}})
}
return output;
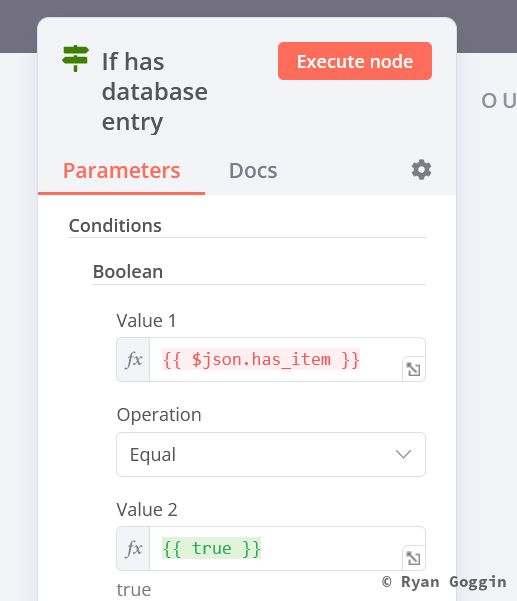
Create an IF node (in database) to check if the task exists in the database (has_item == true). Set it up as follows:
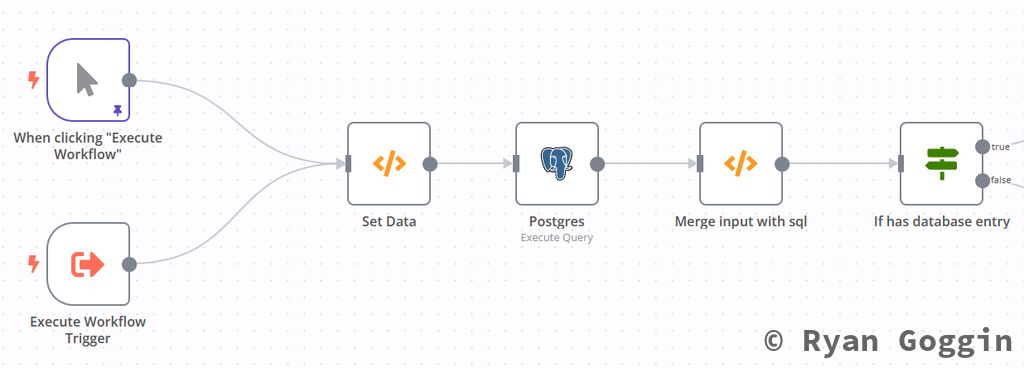
Your workflow should look like this so far:
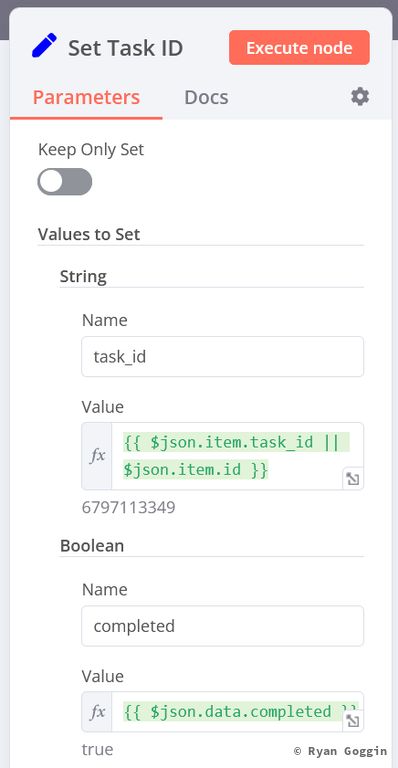
Create branch from the true output on the IF node (in database) and add a set node (Set Task ID) to set the task id from the database (or todoist). Set it up as follows:
Values to set:
- String:
- Name: task_id
-
Value (expression):
{{ $json.item.task_id || $json.item.id }} -
Boolean:
- Name: completed
- Value (expression):
{{ $json.data.completed }}
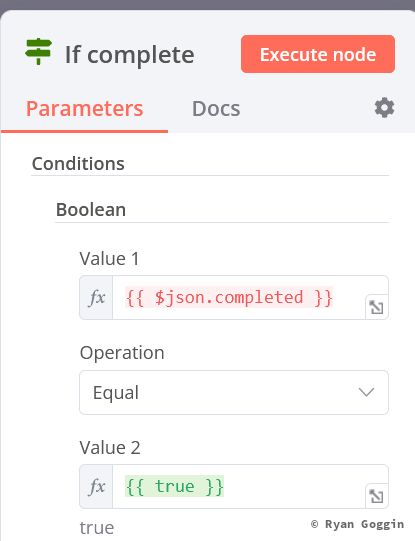
Create an IF node (in todoist and complete) to check if the task is completed. Set it up as follows:
- Boolean:
- Value 1 (expression):
{{ $json.completed }} - Operation:
Equal - Value 2 (expression):
{{ true }}
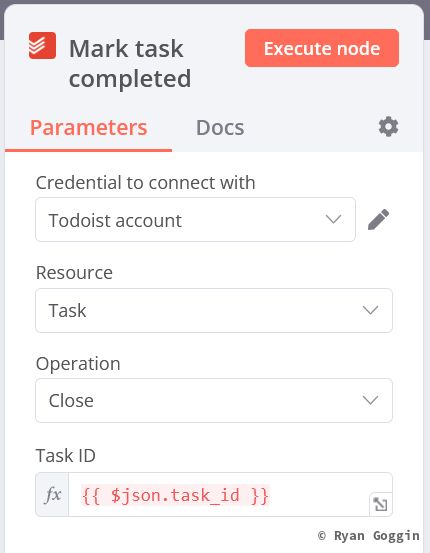
Create branch from the true output on the IF node (in todoist and complete) and create a Todoist - Close a Task node.
Set it up as follows:
- Task ID (expression):
{{ $json.task_id }}
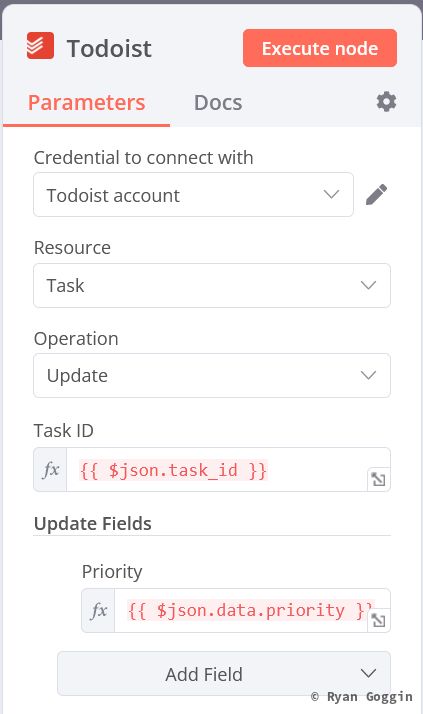
Create branch from the false output on the IF node (in todoist and complete) and create a Todoist - Update a Task node.
And set it up as follows:
- Task ID (expression):
{{ $json.task_id }}
Update Fields:
- Priority (expression):
{{ $json.data.priority }}
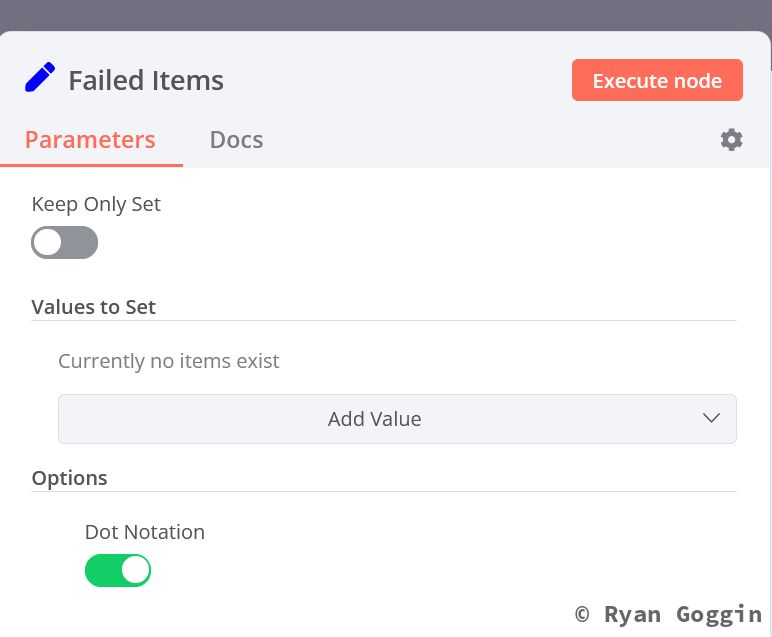
Create branch from the false output of the IF node (in database) and create a Set Node (Failed Items) to reference the items passed down this branch. Just leave settings to default.
Create a Code node to create the queries to check if the task exists in Todoist. Will search multiple in one query, but break it up so that not everything done at once. Set mode to Run One for all Items. Example code here:
var queries = [];
var query = [];
for (const item of $input.all()) {
query.push(`search: ${item.json.key}`)
if (queries.length == 0) {
queries.push({json: {query: query.join(' | ')}})
query = []
}
}
if (query.length > 0) {
queries.push({json: {query: query.join(' | ')}})
}
return queries
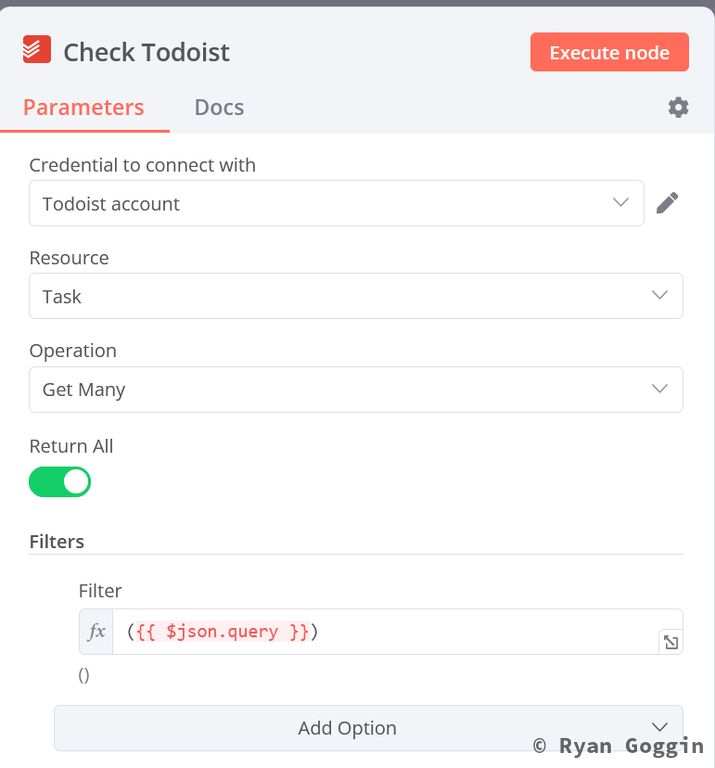
Create a Todoist - Get Many Tasks (Todoist Query) node to check if the task exists in Todoist. Set it up as follows:
- Return All: yes
- Filters:
- Filter (expression):
{{ $json.query }}
Create Code node to merge the data with the Todoist Query output. Set mode to Run One for all Items. The code loops over the Failed Items node and then checks if it matches any result from the Todoist Query node. Example code here:
const output = [];
for (const [idx, code] of $('Failed Items').all().entries()) {
const input = $('Failed Items').all()[code.pairedItem.item]
const k = $('Check Todoist').all().filter(i => i.json.content?i.json.content.includes(code.json.key):false) || [];
output.push({json: {key: code.json.key, has_item: k.length != 0, item: k.length > 0?k[0].json:null, data: {...input.json.data}}});
}
return output;
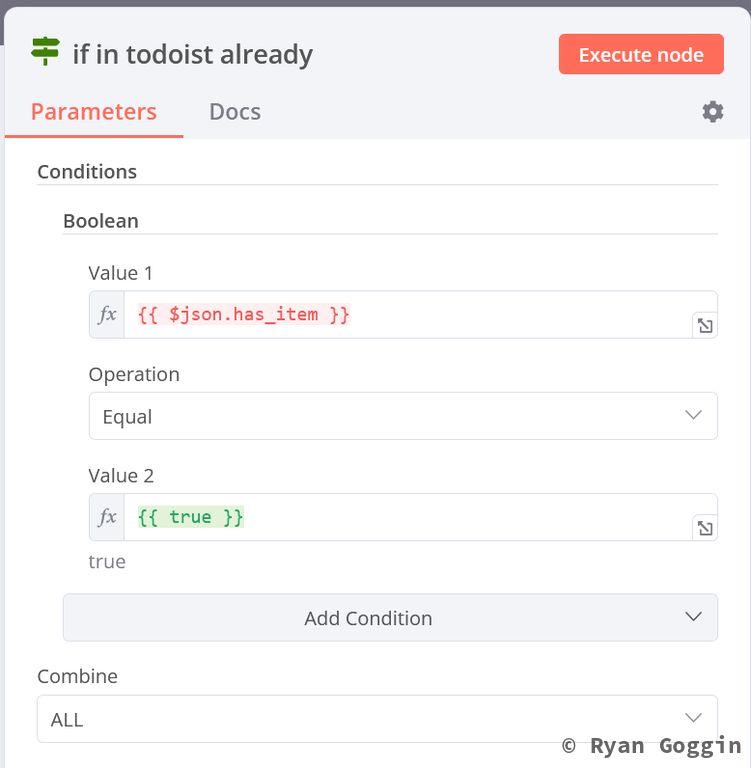
Create an IF node (in todoist already) to check if the task exists in Todoist (has_item == true). Set it up as follows:
Conditions:
- Boolean:
- Value 1 (expression):
{{ $json.has_item }} - Operation:
Equal - Value 2 (expression):
{{ true }}
From the true output of the IF node (in todoist already), connect it to the Set Task ID node created earlier.
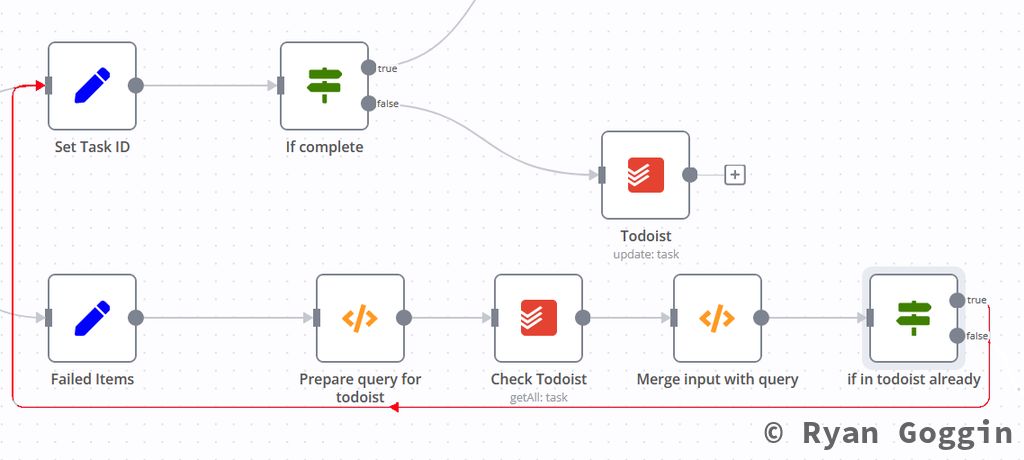
From the false output of the IF node (in todoist already), create an IF node (if already completed). Set it up as follows:
Conditions:
- Boolean
- Value 1 (expression):
{{ $json.data.completed }} - Operation:
Equal - Value 2 (expression):
{{ true }}
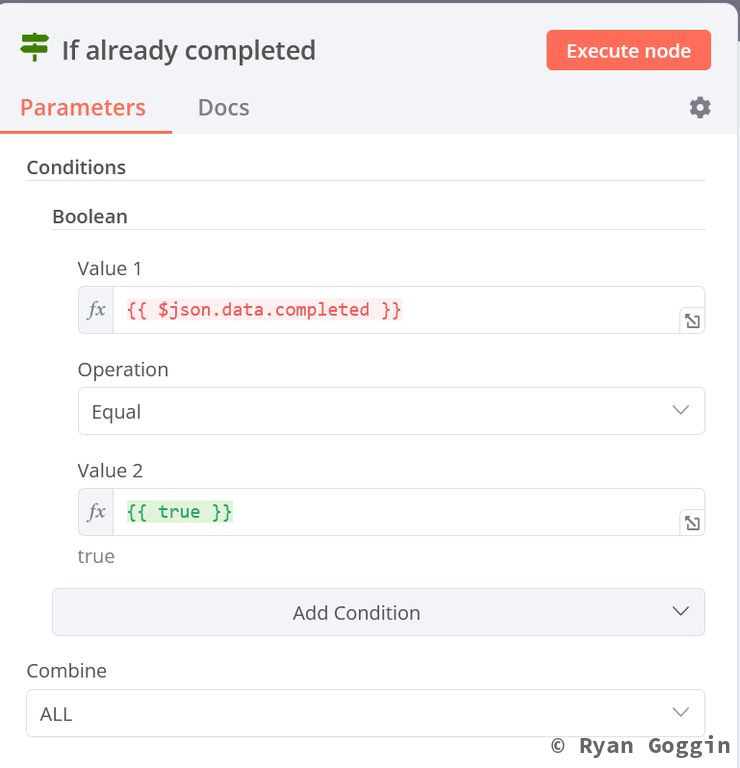
From the true output of the IF node (if already completed), create a No Operation, do nothing node (already completed, don't need to create).
From the false output of the IF node (if already completed), create a Todoist - Create a Task node (Create task since doesn't exist). Set it up as follows:
- Project Name or ID: Select project (or use expression if you are doing this dynamically)
- Label Names or IDs (expression):
{{ $json.data.labels || [] }} - Content (expression):
{{ $json.key }}{{ $json.key }} [{{ $json.data.title }}]({{ $json.data.url }}) - Additional Fields
- Due String (expression):
{{ $json.data.due || "" }} - Priority (expression):
{{ $json.data.priority || 1 }} - Section Name or ID (expression):
{{ $json.data.section }}
The next post in the series will go over creating workflows to pull from task sources and pass to this newly created workflow to create tasks in Todoist.